With the need to stay competitive and make data-driven decisions, companies are increasingly making use of web scraping with Python. In this blog, we will learn how to leverage this powerful tool for extracting data using Python.
You may be a virtuoso or a layman in the universe of programming. But anyone who’s even distantly related to this field has surely heard of Python: the high-level, general-purpose programming language aka the Earth of the programming universe.
And why do we say that? Analogous to Earth which is the most populated planet in the Solar system, Python is the main coding language of 80% of developers. Python is the choice of tool for web scraping for many people out there due to its ease of use, facile syntax, extensive libraries, small codes for executing large tasks, and because it is both strong and dynamically typed.
Additionally, due to its robust nature, it can also be used to scrape Google, Amazon, and other dynamic websites, enabling users to gather and analyze data for various applications including market research, price monitoring, and competitor analysis. This metaphorical comparison gives us several insights into the many traits of Python (not the snake):
- Adaptability: Earth supports diverse ecosystems and life forms. On a similar scale, Python’s versatility is used for web development, scientific computing, data analysis, AI, and more.
- User-friendly: Earth is the most hospitable planet, and Python is the most simplistic and readable language.
- Extensive Libraries: Like the many natural resources of our home planet, Python’s libraries provide powerful tools and resources to make development faster and more efficient.
- Community-driven: Akin to collaboration and knowledge sharing among inhabitants of Earth, Python has a solid and supportive community, fostering innovation.
- Balance: Earth is a habitat for simple organisms and complex life forms. Meanwhile, Python strikes a balance between being beginner-friendly and providing advanced features.
What Is Web Scraping?
Now that we’ve understood why developers widely favour Python, we dig into a common application: Web Scraping with Python. Conventionally, web scraping refers to the practice of using an automated method to extract and collect large amounts of data from websites in unstructured forms and storing it in structured formats.
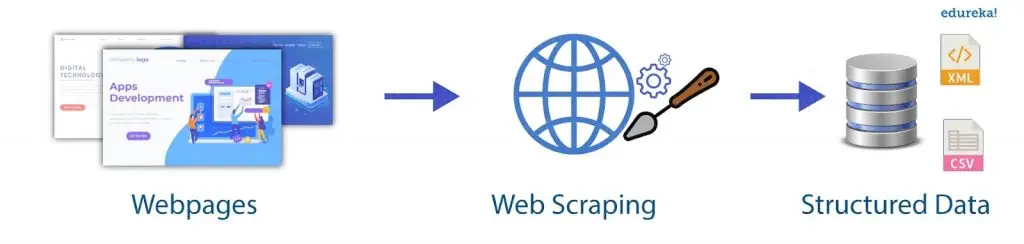
Today, companies use web scraping for extracting data using Python to collect the contact information of potential clients along with price comparison, social media scraping (collect data from social media websites to see what’s trending), research & development, and job listings.
We don’t want to scare you, but if you ever tweeted during a Stranger Things episode, it’s possible that Netflix scraped and analyzed your post to learn how fans are responding to the production on social media.
Python is the choice of tool for web scraping for many people out there due to its ease of use, facile syntax, extensive libraries, small codes for executing large tasks, and because it is both strong and dynamically typed.
Therefore, it is in the best interest of companies to hire Python developers to leverage the benefits of web scraping. Many businesses often inquire, How Much Does It Cost To Hire Python Developers The cost can vary based on experience, location, and the complexity of the project at hand. It’s crucial to balance the budget with the quality and expertise required for your specific needs. Conducting thorough research and comparing prices can lead to making an informed decision.
Is Web Scraping Legal?
To scrape or not to scrape? This is a legal dilemma faced by many companies in the past two decades. While not all web scraping acts are illegal, sometimes they may result in legal concerns.
Web Scraping of publicly available data using Python libraries is legal, whereas web-scraping of data that is non-public and not accessible to everyone on the web is both illegal and unethical.
In the past, there have been several cases where companies were found on the wrong side of ethical conduct.
One such case was Facebook vs Power.com: the firm collected and stored information of Facebook users which was later used to display on their website. Needless to say, Power Ventures invited legal trouble by indulging in this practice and Facebook sued them.
You can easily find out if a website allows web scraping with Python by looking at its “robots.txt” file. To do this, just add the appendage “/robots.txt” to the URL of your choice. For example https://www.youtube.com/robots.txt
Now, let’s explore some libraries that can help you extract data using Python.
Top 5 Python Libraries for Web Scraping
1. Beautiful Soup
Beautiful Soup, a popular Python web scraping library, is widely used for parsing HTML and XML documents. Its user-friendly interface and automated encoding conversions simplify the process of extracting data from websites.
The latest release, BeautifulSoup 4.11.1, offers convenient methods for navigating and modifying parse trees, along with automatic encoding detection.
Although it lacks advanced features like middleware support or multi-threading, Beautiful Soup’s simplicity and compatibility with different parsers make it an ideal choice for beginners in web scraping.
2. Scrapy
Scrapy, a Python framework designed for large-scale web scraping projects, offers a comprehensive solution for extracting data from the web.
Unlike Beautiful Soup, Scrapy excels in its advanced functionality and efficiency. It provides a range of features including request handling, proxy implementation, and data extraction using selectors based on XPath or CSS elements.
With its asynchronous processing and built-in support for various tasks like monitoring and data mining, it is considered the most powerful and fastest web scraping framework available.
While Scrappy may initially appear complex, its capabilities make it an excellent choice for extracting data using Python, reinforcing the language’s position as the ideal programming language for such tasks.
3. Selenium
Selenium is a versatile web testing framework that is particularly useful for scraping dynamic, JavaScript-rendered content. It allows you to mimic user interactions and extract required data by launching a browser instance using the web driver.
While it requires more resources compared to Scrappy or Beautiful Soup, Selenium’s ability to handle JavaScript and work with various programming languages makes it a powerful tool for web scraping with Python.
Additionally, Selenium provides features like access to a JavaScript code interpreter, compatibility with different browsers, and the option to skip image rendering for faster scraping.
4. Requests
Requests is a widely-used Python library for handling HTTP requests, offering a user-friendly approach to working with HTTP. It supports various request types, customizable headers, and handling of timeouts, redirects, and sessions.
While commonly used alongside Beautiful Soup for web scraping with Python, requests can also be utilized independently to generate multiple HTTP requests and retrieve data from web pages.
Additionally, it provides features such as error handling and SSL certificate validation, making it a versatile tool for interacting with web servers and Python web scraping.
5. Urllib3
Urllib3 is a widely used library for web scraping with Python that is similar to the requests library. It provides a simple user interface for retrieving URLs and supports various protocols. With urllib3, you can handle tasks like authentication, cookies, and proxies.
The library also offers features for handling exceptions, modifying headers, and parsing URLs, making it a valuable tool for web scraping tasks. Additionally, urllib3 allows you to examine a website’s robots.txt file for adhering to scraping guidelines.
Web Scraping In Action
To perform web scraping using Python, the following steps are involved:
- Identify the specific URL that you intend to scrape.
- Conduct a thorough inspection of the webpage to understand its structure and elements.
- Determine the specific data you wish to extract from the webpage.
- Write the necessary code to automate the scraping process.
- Execute the code to initiate the scraping and retrieve the desired data.
- Organize and store the extracted data in the format required for further analysis or usage.
In the following example, we will be using BeautifulSoup to scrape product information from Amazon.com and save the details in a CSV file.
Pre-requisites:
- url.txt: A text file with a few URLs of Amazon product pages to scrape
- Element Id: We need Id’s objects we wish to web-scrape
The text file will look like this:

Module needed and installation:
BeautifulSoup: Our primary module contains a method to access a webpage over HTTP.
pip install bs4
lxml: Helper library to process webpages in Python language.
pip install lxml
requests: Makes the process of sending HTTP requests flawless.the output of the function
Step 1: Initialize the Program
The code imports the necessary libraries, Beautiful Soup, and Requests, for web scraping. It then proceeds to create or open a CSV file to store the collected data. A header is declared, and a user agent is added to the request headers. This helps prevent the target website from perceiving the program’s traffic as spam and potentially blocking it.
from bs4 import BeautifulSoup
import requests
File = open("out.csv", "a")
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content, "lxml")Step 2: Retrieving Element IDs
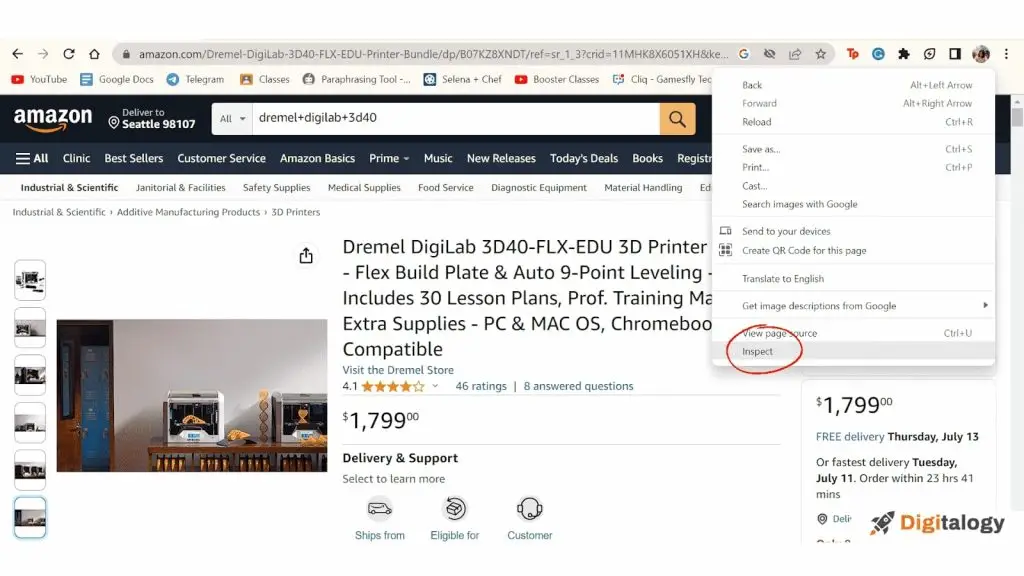
To identify elements within a web page, one typically relies on inspecting the rendered web pages visually. However, the same cannot be said for a script. To precisely locate the desired element, the script needs to obtain its element id and utilize it as input.
Obtaining the element id is a straightforward process. Assuming the script requires the element ID of a product’s name, one can follow these steps:
- Visit the desired URL and inspect the webpage.
- In the browser’s console, extract the text adjacent to the “id=” attribute.
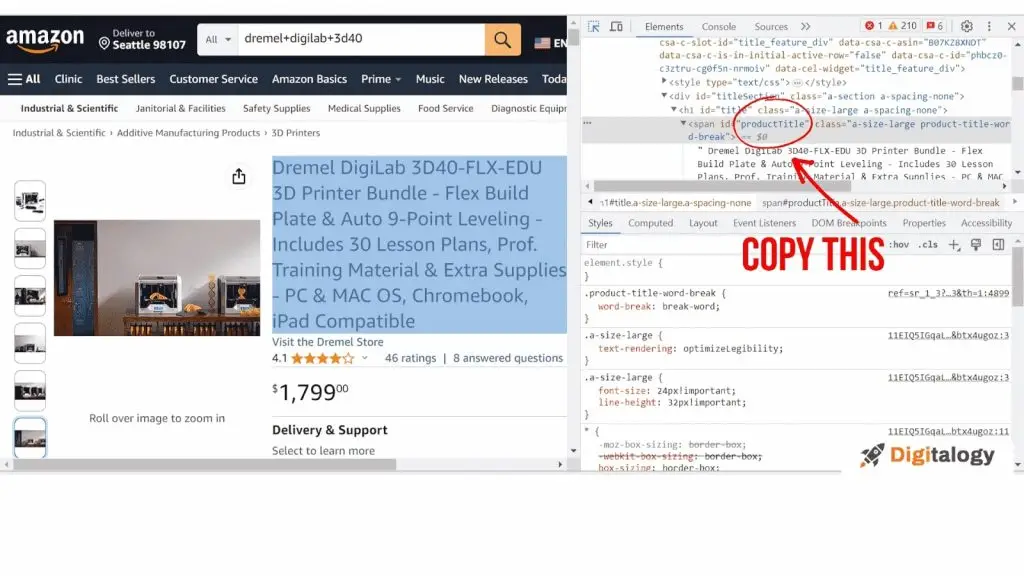
The obtained element id is then passed as an argument to the soup.find() function. The function is used to locate and retrieve the specific element from the web page. The output of the function is converted into a string format.
To ensure compatibility with the CSV try-except writing format, any commas present in the string are removed. This prevents any interference that commas could cause when writing the data to the CSV file.
try:
= soup.find("span",
attrs={"id": 'productTitle'})
title_value = title.string
title_string = title_value
.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)Step 3: Saving current information to a text file
In the process of capturing data from the web, the individual utilizes a file object and employs it to write the recently acquired string. To ensure proper interpretation of the data in a CSV format, a comma “,” is appended at the end of each string, serving as a separator between columns.
File.write(f"{title_string},")This approach is repeated for all the desired attributes, such as Item price and availability, allowing the individual to systematically gather and organize the required information.
Step 4: Closing the file
File.write(f"{available},n")
# closing the file
File.close()In the final step of writing the last piece of information, it is important to observe the inclusion of the escape sequence “n” to introduce a line break. Failing to add this would result in all the required data being placed in a single lengthy row. To ensure the proper handling of the file, the individual concludes the process by invoking the File.close() method. This step is crucial to avoid encountering errors when attempting to open the file again in subsequent operations.
Step 5: Calling the function created
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)The individual opens “url.txt” in read mode and iterates over each line, calling the main function for processing until reaching the last line.
Output:
product Title = Dremel DigiLab 3D40 Flex 3D Printer w/Extra Supplies 30 Lesson Plans Professional Development Course Flexible Build Plate Automated 9-Point Leveling PC & MAC OS Chromebook iPad Compatible
Products price = $1699.00
Overall rating = 4.1 out of 5 stars
Total reviews = 40 ratings
Availability = In Stock.
product Title = Comgrow Creality Ender 3 Pro 3D Printer with Removable Build Surface Plate and UL Certified Power Supply 220x220x250mm
Products price = NA
Overall rating = 4.6 out of 5 stars
Total reviews = 2509 ratings
Availability = NA
product Title = Dremel Digilab 3D20 3D Printer Idea Builder for Brand New Hobbyists and Tinkerers
Products price = $679.00
Overall rating = 4.5 out of 5 stars
Total reviews = 584 ratings
Availability = In Stock.
product Title = Dremel DigiLab 3D45 Award Winning 3D Printer w/Filament PC & MAC OS Chromebook iPad Compatible Network-Friendly Built-in HD Camera Heated Build Plate Nylon ECO ABS PETG PLA Print Capability
Products price = $1710.81
Overall rating = 4.5 out of 5 stars
Total reviews = 351 ratings
Availability = In Stock.
Here’s what the out.csv looks like.

Closing Points
The libraries offer a powerful toolkit for web scraping with Python, enabling developers to extract and collect data from websites efficiently. With resources such as BeautifulSoup, Scrapy, Selenium, requests, and urllib3, developers can access a wealth of tools and functionalities.
To learn more about these libraries and Python web scraping, online tutorials, documentation, and interactive courses are available, while hands-on projects provide valuable practical experience. It is crucial to approach web scraping ethically, respecting legal guidelines and website terms.
By diving into Python libraries and undertaking practical projects, developers can gain the expertise needed to navigate web scraping, unlocking valuable insights from the vast digital landscape.